 武大金融网
武大金融网rvest包是hadley大神的又一力作,使用它能更方便地提取网页上的信息,包括文本、数字、表格等,本文对rvest包的运用做一个详细介绍,希望能够帮助你在网页抓取的武器库中新添一把利器。看本文之前需要你对html有一个基本的了解,如果你完全不了解html,那么希望你能先花几分钟时间了解以下问题:
- 什么是html?html是由哪些部分组成?
- 什么是html标签?html中的元素、属性、id指的又是什么?
- CSS的定义?CSS selector的作用?
rvest安装
从CRAN上安装发行版:
install.packages("rvest")也可以从github上安装开发版本:
install.packages("devtools")
devtools::install_github("hadley/rvest")rvest用法简介
下面对rvest包中的主要函数的功能做一下说明:
read_html()读取html文档的函数,其输入可以是线上的url,也可以是本地的html文件,甚至是包含html的字符串也可以。html_nodes()选择提取文档中制定元素的部分。可以使用css selectors,例如html_nodes(doc, "table td");也可以使用xpath selectors,例如html_nodes(doc, xpath = "//table//td")。本文后面的示例主要采用css selectors来提取html文档中我们想要的部分。html_tag()提取标签名称;html_text()提取标签内的文本;html_attr()提取指定属性的内容;html_attrs()提取所有的属性名称及其内容;html_table()解析网页数据表的数据到R的数据框中。html_form(),set_values()和submit_form()分别表示提取、修改和提交表单。- 在中文网页中我们经常会遇到乱码的问题,这里提供了两个函数来解决:
guess_encoding()用来探测文档的编码,方便我们在读入html文档时设置正确的编码格式,repair_encoding()用来修复html文档读入后的乱码问题。 - 还有一些函数,用来模拟网上的浏览行为,如
html_session(),jump_to(),follow_link(),back(),forward(),submit_form()等等,这部分的工作还在进行中,相信rvest也会越来越强大。
以上就是rvest包的主要功能函数,下面我们来尝试用rvest包中的函数抓取新赛季NBA常规赛首日的新浪NBA首页的新闻消息。
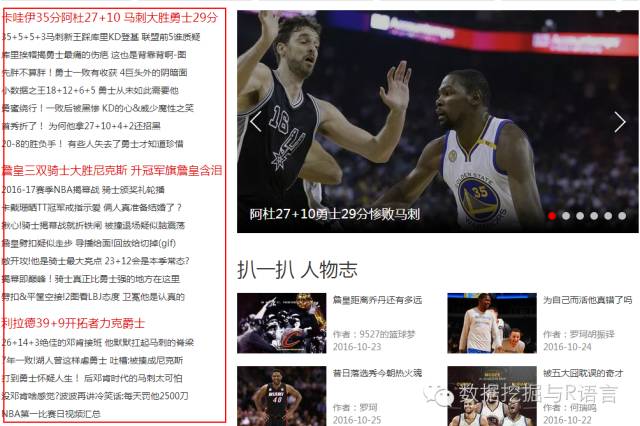
示例图片
抓取示例
网页抓取的一般步骤我总结有如下三步:
- 首先,明确所要抓取的内容
- 然后,通过html的标签名称、属性以及id等确切的描述定位到该内容的位置
- 最后,提取相关的内容信息,必要时再做一些数据处理
载入rvest包,读取新浪NBA官网网页
library(rvest) # version 0.3.2
url = 'http://sports.sina.com.cn/nba/'
web = read_html(url)抓取最新的NBA新闻消息列表
html_nodes(web,".news-list-b a") %>% html_text ## [1] "卡哇伊35分阿杜27+10 马刺大胜勇士29分"
## [2] "35+5+5+3马刺新王踩库里KD登基 联盟前5谁质疑"
## [3] "库里挨帽揭勇士最痛的伤疤 这也是背靠背啊-图"
## [4] "先胖不算胖!勇士一败有收获 4巨头外的阴暗面"
## [5] "小数据之王18+12+6+5 勇士从未如此需要他"
## [6] "勇蜜绕行!一败后被黑惨 KD的心&威少魔性之笑"
## [7] "首秀折了! 为何他拿27+10+4+2还招黑"
## [8] "20-8的胜负手! 有些人失去了勇士才知道珍惜"
## [9] "詹皇三双骑士大胜尼克斯"
## [10] "升冠军旗詹皇含泪"
## [11] "2016-17赛季NBA揭幕战 骑士颁奖礼轮播"
## [12] "相爱相杀!他是甜瓜最不想输的敌(peng)人(you)"
## [13] "卡戴珊晒TT冠军戒指示爱 俩人真准备结婚了?"
## [14] "揪心!骑士揭幕战就折铁闸 被撞退场疑似脑震荡"
## [15] "詹皇劈扣疑似走步 导播给面!回放给切掉(gif)"
## [16] "敞开攻!他是骑士最大亮点 23+12会是本季常态?"
## [17] "揭幕即巅峰!骑士真正比勇士强的地方在这里"
## [18] "利拉德39+9开拓者力克爵士"
## [19] "神吐槽:能跑赢詹皇的只有裁判 铁林江山不保"
## [20] "人物|他曾几乎无球可打 如今却令全世界赞叹"
## [21] "26+14+3绝佳的邓肯接班 他默默扛起马刺的脊梁"
## [22] "7年一败!湖人曾这样虐勇士 吐槽:被揍成尼克斯"
## [23] "NBA第一比赛日视频汇总"
## [24] "50大第1星:詹姆斯"
## [25] "詹皇联手甜瓜?"
## [26] "哈登谈揭幕战:首次面对没科比的湖人感觉奇怪"
## [27] "KD羡慕猛龙双枪友情:和威少之间未有过"
## [28] "不播了!央视首月直播减湖人7场 留战勇士马刺"抓取NBA新闻热点
html_nodes(web,".txt-a-hilight") %>% html_text ## [1] "卡哇伊35分阿杜27+10 马刺大胜勇士29分"
## [2] "詹皇三双骑士大胜尼克斯"
## [3] "升冠军旗詹皇含泪"
## [4] "利拉德39+9开拓者力克爵士"
## [5] "50大第1星:詹姆斯"
## [6] "詹皇联手甜瓜?"
## [7] "KD羡慕猛龙双枪友情:和威少之间未有过"抓取NBA新闻头条
html_nodes(web,"#__liveLayoutContainer :nth-child(2) .txt-a-hilight") %>% html_text ## [1] "卡哇伊35分阿杜27+10 马刺大胜勇士29分"可以看到,如果想要准确的提取相关新闻消息,需要用css选择器准确地描述消息所处的位置,如.news-list-b a、.txt-a-hilight等。如果你熟悉css选择器,你将会很容易通过查看html的源代码来定位所要提取内容的位置。如果你不太熟悉,这个我们的大神也考虑到了,你可以直接使用一个基于JS的小工具来实现定位,插件的使用参见vignette("selectorgadget")。
以上提取的主要是文本信息,对于网页中表格中的数据可以直接采用html_table()来获取,这部分示例详见微信公众号中案例数据的代码。一些复杂的模拟网上浏览行为的函数待rvest版本更新升级后我再做进一步的介绍。
特别说明
该示例结果为2016年10月26日下午5点运行得出,该演示代码及结果具有一定的时效性,大家在演示代码的时候如有任何问题可直接留言,我会争取在第一时间回复,谢谢!
未经允许不得转载:武大金融网 » 【大数据】网页爬取利器——rvest